Getting Started » Core Concepts
Before you start writing any data access code with ROM, it's a good idea to get a high level overview of what each major component is and its overall purpose.
ROM fundamentally is a series of abstractions built on one another to create a very flexible system for accessing and manipulating complex data in your applications.
The following diagram shows an overview of the ROM architecture and provides an outline of how data flows within a ROM based data access layer. Further down is a basic explanation of each component.
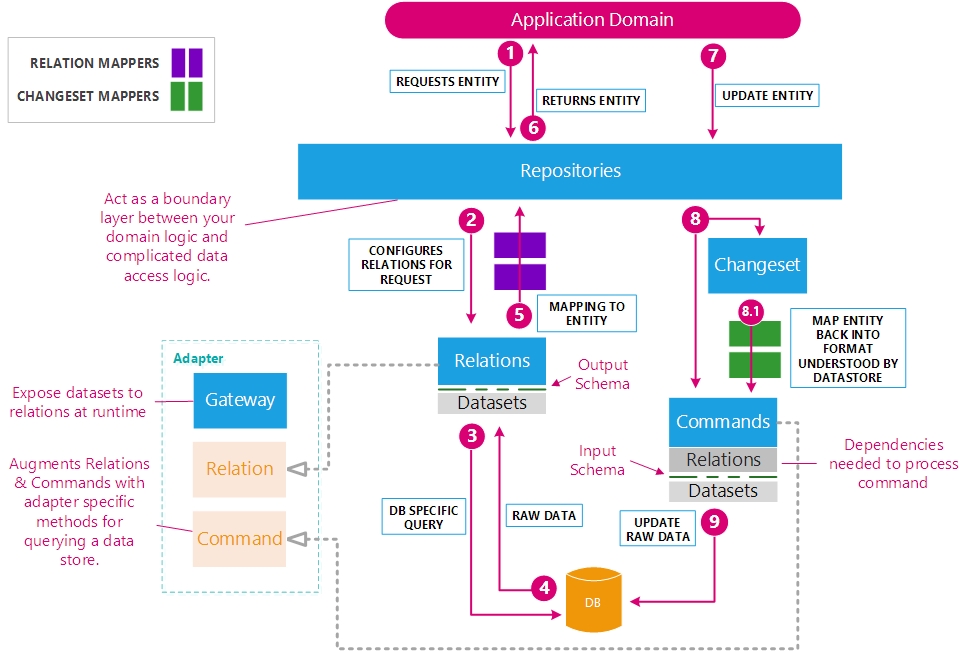
Data flow
Reading Data
Step 1: Application Domain has a need for a particular entity/entities so it calls into the appropriate repository and asks for an entity
Step 2. The Repository accepts the request and combines all of the related associations together to create a datastore-specific query for the data
Step 3. Once a relation has been composed of all needed restrictions or
selections, the relations #each method is called which triggers
the dataset to fetch the data.
Step 4. Raw data in the form of tuples are collected from the datastore and returned to the relation. Before proceeding each tuple is passed through an output schema.
Step 5. The relation, if mappers are configured, maps the tuples into an output entity/entities.
Step 6. The repository passes the entity/entities on through to the Application Domain.
Writing Data
Writing data with ROM is fundamentally a process of applying commands to relations in order to modify the stored data.
Step 7. Application Domain has a need to update an entity.
Step 8. The repository, accepting either an entity object or a raw Hash
representing the entity, configures either a changeset or direct
command on relation to make changes to the datastore.
Step 8.1. Before the Changeset passes itself to the underlying command, you can map the Changeset data into a structure that's more akin to what your datastore looks like.
Step 9. Command processes one or more tuples through the input schema then executes against the datastore which updates the data.
Repositories
Repositories provide a powerful CRUD interface built on top of relation, mapping and command APIs. They give you a simple way for composing data provided by relations, automatically mapping data to structs or custom object types and expose simple access to commands with support for changesets.
An important function of repositories is to act as a boundary between the data access logic and Application Domain logic. This boundary helps to reduce the complexity of rehydrating your entities and keeps a direct dependency on a particular datastore out of your domain.
To learn more about repositories, how to use them and their role in a system developed using ROM, check out the Repositories section.
Repositories are completely optional and while they provide powerful features for encapsulating data access logic, they may not make sense for some simple CRUD applications or one-off scripts.
Relations
A relation is defined as a set of tuples identified by unique pairs of
attributes and their values. In ROM it is an object that responds to #each
which yields hashes. It is backed by a dataset object provided by
the adapter.
An example of relations are tables in a SQL server. Tables can reference other tables and sometimes all of the pieces for some "view" of the data are spread out among two or more tables (think Multi Table Inheritance). In situations like this ROM really shines because relations can be created for each table and composed together to pull the data into a coherent form then finally mapped to an output object which your application can depend on safely without worrying about shared state, sessions or identity mapping commonly used in other ORMs.
To learn more about relations, check out the Relations guide.
Commands
Commands in ROM are intended to safely modify data. Commands can be used to create, update and delete. They are usually provided by the adapter, but you may define your own.
To learn more about commands, check out the Commands guide.
Relation Mappers
A mapper is an object that takes a relation and maps it into a different representation. Mappers are generated automatically and in typical cases you don't have to define them; however, ROM provides a DSL to define custom mappings or you can register your own mapper objects for custom, non-standard queries, or complex cross-datastore mappings.
To learn more about mappers, check out the Mappers guide.
Changesets
Built on-top of commands, changesets are an optional tool for making changes in your database. The power of changesets comes from the ability to take input data and optionally convert it into a representation that's more compatible with your database schema before it passes into a command.
Changesets also make updating aggregate entities much easier by automatically handling associations between multiple relations. This makes deconstructing a complex entity and updating its individual pieces much easier.
To learn more about changesets, check out the Changesets guide.
Adapters
ROM uses adapters to connect to different data sources (a database, a csv file -
it doesn't matter) and exposes a native CRUD interface to its relations. Every
adapter has extension points to support database-specific functionality.
It provides its own relation types, extensions for built-in commands, and
potentially new command types. Furthermore, an adapter can provide extra
features that are needed to work with a given database type. For example,
rom-sql provides Migration API for managing the schema in a SQL database.
Remember all of the abstractions provided by ROM are ultimately there to separate any hard dependencies higher up in the application stack. So when creating relations, take advantage of that separation by not leaking adapter implementation details.
Gateways
An object that encapsulates access to a specific persistence backend. ROM supports loading multiple gateways allowing an application to pull from multiple data sources easily, including cross-datastore relations.
Gateways are provided by the adapter and after ROM finishing loading they're generally hidden behind the scenes.
Datasets
Only exposed as a private interface to Relations, datasets act as the middle-man between relations and datastores.
For example, in the SQL adapter, datasets provide the join functionality where columns in other tables can be joined together via foreign_keys. This is a prime example of relations (thru datasets) taking advantage of what the storage engine can offer while also hiding those implementation details away from the application.